
공부하는 스누피
[컴퓨터구조] 캐시 (cache) 본문

캐시
캐시는 메모리 접근의 지역성을 이용하는 장치이다.
프로세스가 캐시에 없는 워드를 요청하면 fault를 발생시켜서 해당 워드를 캐시로 가져오게 한다.
캐시는 메모리 장치 간의 속도차로 인한 병목 현상을 예방해 주는 장치인데, 예를 들어 CPU와 메인 메모리 간의 속도가 1,000,000배 차이난다면, 두 장치와 속도차가 1000배씩 차이나는 캐시를 중간에 하나 추가해주어 각 메모리 간의 속도차를 1000배씩 줄여준다.
(예시)
CPU (1,000,000) --- Main Memory (1)
=> CPU는 1초에 1,000,000개의 데이터 교환이 가능한데 Main Memory는 1개만 가능하다.
=> 그렇게 되면 CPU에서 메인 메모리에 1,000,000개의 데이터를 보내는 데 1,000,000초가 걸린다. (병목 현상)
CPU (1,000,000) --- Cache(1,000) --- Main Memory (1)
=> CPU는 1초에 1,000,000개의 데이터 교환이 가능하고, 캐시 메모리는 1,000개만 가능하다.
=> 그렇다면 CPU에서 캐시로 1,000,000개의 데이터를 보내는 데 1,000초가 걸린다. 한번에 1,000개씩 받는다.
=> 캐시에서 메인 메모리로 1,000개의 데이터를 보내는 데 1,000초가 걸린다.
=> 이때, CPU에서 캐시로 데이터를 보내는 과정과 캐시에서 메인 메모리로 데이터를 보내는 과정이 같이 수행된다. 그래서 두 과정을 직렬로 수행한 1,000 * 1,000 = 1,000,000초보다 빨리 수행할 수 있다.
=> 따라서 캐시가 없을 때보다 훨씬 빠르다.
캐시는 예측기법을 사용한다.
- 지역성의 원칙을 이용해서 메모리 상위 계층에서 필요한 데이터를 찾는다.
- 예측이 틀렸을 경우 하위 계층에서 적합한 데이터를 찾는다.
캐시는 공간적 지역성을 이용해 메모리의 워드를 필요한 워드만 갖고 오는 것이 아니라 주변 워드를 포함한 블록 단위로 가져 온다. 블록 크기가 클수록 캐시 실패율이 감소하지만, 실패할 경우 손실이 증가한다. 블록 크기가 작을수록 실패율은 증가하지만, 손실은 감소한다.
캐시 데이터 매핑
Direct Mapping
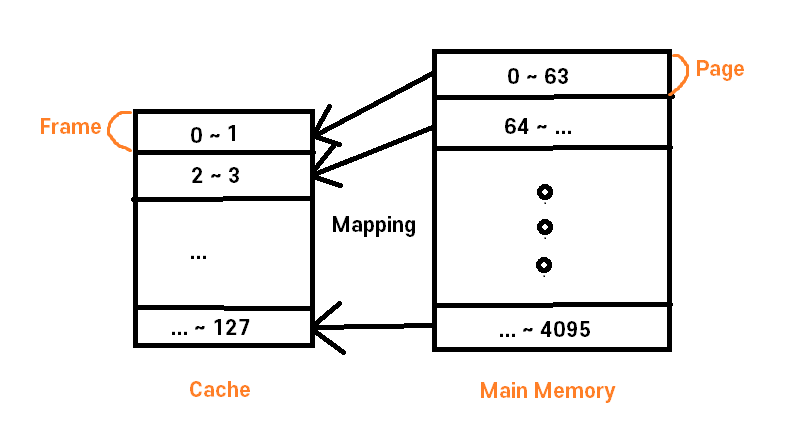
- 프레임 번호 당 같은 범위의 순차적인 페이지를 매핑한다.
=> 예를 들어, 캐시 메모리의 크기가 128이고, 메인 메모리의 크기가 4096이라고 하자.
=> 캐시 메모리의 프레임은 메인 메모리의 페이지에 있는 워드들이 담기는 공간으로, 2라고 하자.
=> 캐시 메모리의 첫 번째 프레임에는 메인 메모리의 0번~63번까지의 페이지가 매핑된다.
=> 페이지 크기 * 캐시 메모리 크기 * 캐시 메모리 프레임 크기 = 메인 메모리 크기
=> 64 * 128 * 2 = 4096 이기 때문에 페이지의 크기는 64라는 것을 알 수 있다.
- 각 주소 값이 캐시메모리에 바로 대응되지 않는다. 지역 참조성 때문.
(예시에서는 이해를 돕기 위해 바로 대응되는 것처럼 그렸음)
=> 공간 지역성에 따라, 2번 주소의 데이터가 요청될 경우 근처 주소에 있는 데이터도 나중에 요청될 확률이 크다.
=> 따라서 1, 3번 주소의 데이터도 요청될 확률이 크다.
=> 이때 Direct Mapping으로 1, 2, 3번 주소를 한 페이지로 처리해버리면 한정된 프레임에서만 이 주소들이 저장된다.
=> 이로 인해 cache miss를 유발할 가능성이 크다. (프레임이 3 미만일 경우)
=> 그래서 페이지 내의 주소를 순차적으로 넣지 않고 분산시킨다.
=> 예를 들어 1번 프레임에 할당될 페이지에 1번 주소를 할당하고,
=> 2번 프레임에 할당될 페이지에는 2번 주소를 할당한다. 3번도 마찬가지로 할당한다.
=> 그러면 자주 접근할 확률이 높은 데이터들이 동시에 캐시에 올라올 수 있게 된다.
- 페이지 교체 알고리즘을 사용하지 않는다.
Fully Associative Mapping
- 메인 메모리의 어떤 프레임도 캐시메모리의 모든 곳에 매핑될 수 있다.
=> 캐시 메모리에서 데이터를 찾을 때 시간이 오래 걸린다.
- CAM(Content Addressible Memory)이라는 워드를 사용한다.
=> CAM은 Direct Mapping의 워드에서 태그 필드를 추가해서 빠른 검색을 할 수 있게 한다.
Set-Associative Mapping
- Direct Mapping과 Associative Mapping을 섞었다.
- 캐시 영역을 set으로 나누고, 참조를 위해 워드에 set bit을 사용한다.
=> 원래 tag bit이 12bit였으면, tag bit를 6bit, set bit를 6bit로 한다.
- set 내부에서는 Associative Mapping처럼 접근한다.
Cache Miss
캐시에서 프로세스가 원하는 데이터를 찾지 못하면 cache miss라고 한다. 찾으면 cache hit이라고 한다.
<처리 단계>
1) 원래 PC값을 메모리로 보낸다.
2) 메모리에 읽기 동작을 지시하고, 접근이 끝날때까지 기다린다.
3) 읽은 데이터를 데이터 부분에 쓰고, 유효비트를 1로 해서 캐시 엔트리에 쓰기를 수행한다.
4) 명령어 수행을 cache miss가 발생했떤 첫 단계부터 다시 수행한다.
즉시 쓰기 (write-through)
- 데이터를 캐시와 메모리에 둘 다 쓴다.
- 접근을 기다리는 동안 데이터를 저장하는 쓰기 버퍼로 성능을 향상시킬 수 있다.
나중 쓰기 (write-back)
- 쓰기가 발생하면 새로운 값을 캐시 내의 블록에 쓴다.
- 캐시의 블록이 교체될 때 하위 계층에 해당 데이터를 쓴다.
분할 캐시 (split cache)
- 한 계층이 병렬로 구성된 캐시로 이루어진다.
- 캐시 하나는 명령어만 처리하고, 다른 캐시는 데이터만 처리하게 해서 성능을 높인다.
(참고)
David A. Patterson, John L. Hennessy (2018). Computer Organization and Design (ARM Edition)
www.youtube.com/watch?v=QcAaP5V2Gpc
=> 여기 강의가 도움이 많이 되었다.
'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] 파이프라이닝 (0) | 2020.11.12 |
|---|---|
| [컴퓨터구조] 논리회로 (0) | 2020.11.12 |
| [컴퓨터구조] 부동소수점 (0) | 2020.11.10 |
| [컴퓨터구조] 프로그램 번역과 실행 과정 (0) | 2020.11.08 |
| [컴퓨터구조] 2의 보수 표현법 (two's complement) (0) | 2020.11.07 |

